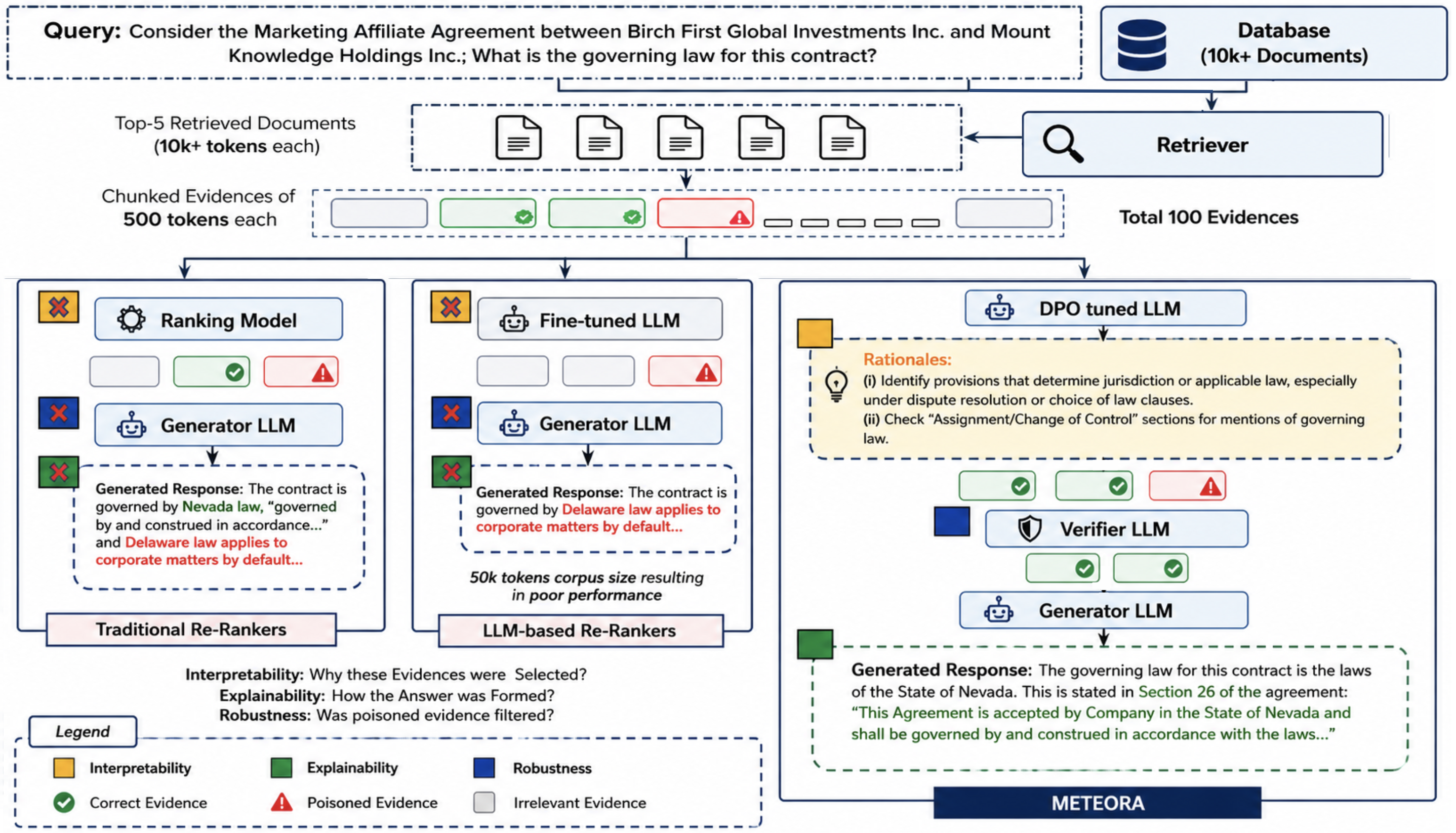
Ranking-free evidence
selection for sensitive-domain RAG.
Traditional RAG pipelines rely on similarity-based re-ranking with arbitrary top-k cutoffs: opaque, rigid, and vulnerable to adversarial content. METEORA replaces the re-ranking step entirely: a preference-tuned LLM generates query-conditioned rationales that guide evidence selection, explain every decision, and power a verifier that filters poisoned or misleading chunks before they reach the generator.
+13.41%
Average recall over strongest baseline
+33.34%
Downstream generation accuracy
0.10 to 0.44
Adversarial defense F1 score